LLM cost optimization is the highest-leverage operational decision you'll make when scaling AI features. Not infrastructure, not model selection: how you route queries across your model tier. A single-model setup that routes every message through your most capable (and expensive) LLM is the equivalent of hiring a senior engineer to answer "what's the return policy?" a thousand times a day.
This guide covers four concrete techniques to reduce LLM costs without degrading quality: confidence-based model routing, response caching, model tiering, and prompt token reduction. We'll get specific on the math, the tradeoffs, and how the confidence_router workflow node implements this in practice.
Why LLM Cost Optimization Matters at Scale
Most bots and AI features start with a single model. It's operationally simple and you're not sure what traffic will look like yet. That's fine early on. But once you're past a few thousand messages a day, it's worth looking at your actual query distribution.
A typical support or assistant bot's query mix looks like this:
| Simple queries (60–70%) | Complex queries (30–40%) | |
|---|---|---|
| Examples | FAQ lookups, order status, greetings, yes/no confirmations | Multi-step reasoning, tool orchestration, ambiguous intent, refund analysis |
| Model needed | Fast, cheap tier (Haiku, GPT-4o-mini, Llama 3.3 70B) | Capable tier (Sonnet, GPT-4o, Claude Opus) |
| Typical cost | $0.25–$3 per 1M input tokens | $10–$15 per 1M input tokens |
| Quality delta | No user-visible difference for retrieval/classification tasks | Capable model meaningfully better for reasoning chains |
The cost delta between tiers is roughly 60×. If 60% of your traffic can use the cheap tier, you're paying top-tier rates on 60% of queries you didn't need to, and that compounds fast at volume.
Four Techniques to Reduce LLM Costs
These four techniques stack. You don't have to implement all of them on day one, but in our experience each one compounds the savings from the others.
1. Confidence-Based Model Routing
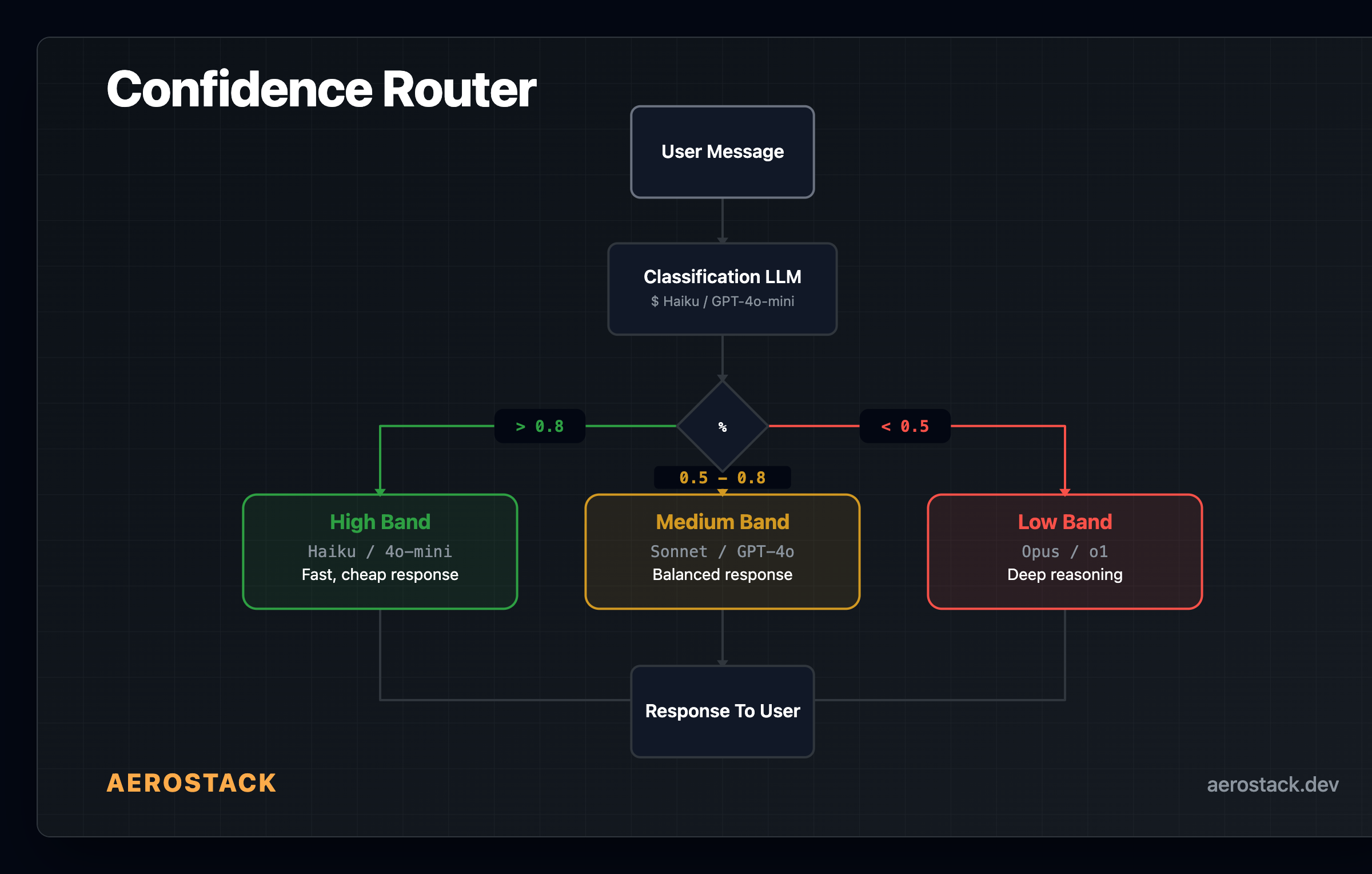
This is the highest-impact LLM cost optimization technique for mixed-complexity workloads. We've found it's usually the first place to start. A lightweight classifier (run on a cheap model) scores each incoming query by complexity. Based on the confidence score, the query routes to one of three model bands: cheap for simple, mid for moderate, capable for complex.
The key insight: you're not degrading quality by using a cheaper model on simple queries; those queries don't need deep reasoning. Routing them to Haiku or GPT-4o-mini produces the same user-visible output at 60× lower cost.
2. Response Caching
High-confidence simple queries are also the most likely to repeat. "What's the return policy?" gets asked by many different users. Cache the response at the gateway layer with a short TTL (5–60 minutes for dynamic content, longer for static FAQ). A cache hit costs $0.00 in inference. This is the fastest implementation win in LLM cost optimization, and it's why we recommend starting here.
3. Model Tiering by Use Case
Not all your AI features need the same model. Classification tasks (intent detection, sentiment, routing) can always use the cheapest tier. Summarization and simple Q&A usually work at the mid tier. Only genuine multi-step reasoning or tool orchestration needs your top model. Map your features to tiers deliberately. Don't default everything to the capable model because it's the "safest" choice.
4. Prompt Token Reduction
Input tokens are often where the money leaks quietly. A bloated system prompt sent on every request (company overview, formatting rules, brand voice, all in one 3,000-token blob) costs you $0.045 per call at top-tier rates. A 500-token focused system prompt drops that to $0.0075. Audit your system prompts. Use structured outputs (JSON mode) to cut output verbosity. Trim conversation history aggressively; most bots only need the last 3–5 turns.
How the confidence_router Implements LLM Cost Optimization
We built the confidence_router as a workflow node that handles classification and routing in a single step. You wire it between your trigger and your response nodes. It does two things in sequence:
Classification. You define intent categories such as ["billing", "technical", "general", "greeting"]. The node sends the message to a lightweight classifier and returns structured JSON: intent label + confidence score between 0 and 1.
Routing. The confidence score maps to one of three outbound edges: high, medium, low, each pointing to a different llm_call node with the appropriate model. Default thresholds are 0.8 (high) and 0.5 (low), both tunable per workflow.
Configuration and BYOK
The node is configurable. You set the intent categories, both confidence thresholds, and optionally specify which model to use for the classification step itself. Our default is the cheapest model available in your workspace. The response models on the three outbound edges are yours to choose. No lock-in.
Model choices work with any provider you've connected: Claude (Haiku/Sonnet/Opus), OpenAI (GPT-4o-mini/GPT-4o), Gemini, Groq, Workers AI, or your own models via BYOK. We've tested this with all of them. The cost math works in your favor regardless of which provider you use; the tier differential exists across all major providers.
{
"node": "confidence_router",
"categories": ["faq", "order_status", "complex_support", "greeting"],
"high_threshold": 0.8,
"low_threshold": 0.5,
"classifier_model": "claude-haiku",
"edges": {
"high": { "model": "claude-haiku", "reason": "simple FAQ, greetings at $0.25/1M" },
"medium": { "model": "claude-sonnet", "reason": "moderate reasoning at $3/1M" },
"low": { "model": "claude-opus", "reason": "complex multi-step at $15/1M" }
}
}Important tradeoff: the classification pass is itself an LLM call. Use your cheapest model for classification. At Haiku pricing (~$0.25/1M tokens), that's roughly $12.50 added to a 100K-query/month workload. You'll still net a significant saving if ≥40% of traffic is simple. The savings come from routing response generation, not from the classification step itself.
The Cost Math: 100K Queries Per Month
Here's the LLM cost optimization math for a support bot at 100K queries/month, 500 tokens average input. We've used this calculation framework to validate the approach; your numbers will vary by traffic mix. Pricing from Anthropic and OpenAI. Check current rates before projecting.
The savings depend on your actual distribution. A restaurant reservation bot might split 80/15/5; savings are larger. A specialized technical support bot might run 30/40/30; savings are smaller but still meaningful. Test your actual traffic before committing to thresholds. The 60/30/10 split above is illustrative.
When Confidence Routing Makes Sense (and When It Doesn't)
Confidence routing is the right LLM cost optimization technique when you've got mixed query complexity and enough volume that per-query savings compound. It's not the right tool for every workload, and we'd rather you know the limits up front.
Good fit:
- Mixed complexity. A meaningful slice of your messages are simple enough for a cheaper model: FAQ, greetings, status, confirmations.
- Volume ≥ 1K/day. Below a few hundred messages daily, the routing setup overhead doesn't pay back quickly.
- Quality tested. You've sampled routed responses and confirmed the cheap model handles simple queries at acceptable quality. If users notice a quality drop, your thresholds need tuning.
Not a fit:
- All queries are complex. Legal analysis, specialized technical support, multi-document synthesis. Use your best model for everything.
- Sub-second latency is critical. The classification pass adds time. Measure the latency tradeoff before committing.
- Volume is too low. Below ~300 messages/day, LLM costs are small enough that simpler approaches like prompt tuning, caching alone return faster.
LLM Routing Within a Gateway Architecture
Confidence routing is one technique inside a larger llm gateway architecture. The gateway handles routing, auth, rate limiting, observability, and caching as a unified control plane across all your models and providers. Confidence routing plugs into it as the query-classification layer, and the gateway's caching and rate-limiting layers handle the other cost levers.
If you're building an llm gateway infrastructure for multiple agents or services, you'll want to apply cost optimization at the gateway level so that every team or agent that routes through it benefits automatically. Autonomous agents and AI coding agents (which can generate bursts of high-volume tool calls) benefit especially from gateway-level routing since their query patterns skew toward the repetitive-simple end.
FAQ: LLM Cost Optimization
What's the most effective way to reduce LLM costs?
The fastest win is response caching; a cache hit costs $0 in inference. For sustained savings at volume, confidence-based routing to a multi-model tier is typically the highest-impact technique, cutting costs 60–83% when ≥60% of queries are simple. Combine both with prompt token reduction (trim system prompts, cut conversation history) for maximum effect.
Does routing to a cheaper model hurt response quality?
For simple queries (FAQ lookups, status checks, greetings, yes/no confirmations), a fast cheap model (Haiku, GPT-4o-mini) produces the same user-visible quality as a top-tier model. The difference only materializes on queries that genuinely need multi-step reasoning or tool orchestration. Threshold tuning and quality sampling before go-live ensures you're only routing queries the cheap model actually handles well.
How does confidence routing work technically?
A lightweight classifier (running on your cheapest model) receives the incoming query and outputs structured JSON: an intent label and a confidence score between 0 and 1. A router reads that score against your configured thresholds and dispatches the query to one of three llm_call nodes, each wired to a different model tier. The classification overhead is small (a cheap model at $0.25/1M tokens adds ~$12.50/month for 100K queries).
What model combinations work best for LLM cost optimization?
A three-tier setup that works well: Haiku or GPT-4o-mini for the cheap tier (FAQ, greetings); Claude Sonnet or GPT-4o for the mid tier (moderate reasoning); Claude Opus or GPT-4 for the capable tier (complex multi-step). You can also use Workers AI models (Llama 3.3 70B) as cost-effective options for the cheap or mid tier. BYOK lets you bring your own API keys for any provider. Model choice stays yours.
Can I use this with multiple AI providers or BYOK models?
Yes. The confidence_router node doesn't care which provider each tier uses. You can wire the cheap tier to Haiku, the mid tier to GPT-4o, and the capable tier to Gemini if that fits your pricing. BYOK lets you bring your own API keys for any provider, so the cost savings apply regardless of which models you choose.
How is LLM routing different from LLM cost optimization?
LLM routing is one technique within the broader LLM cost optimization toolkit. Routing decides which model handles a given query. Cost optimization also includes caching (avoiding the LLM call entirely for repeated queries), token reduction (shrinking input/output size), and use-case tiering (mapping features to the right model tier by default). Routing gives you the biggest per-query savings; caching can eliminate cost entirely for repeating queries.
LLM cost optimization isn't a one-time project. Query distributions shift as your product evolves. A bot that starts with mixed complexity might simplify as you add FAQ tools, or get more complex as you add agent capabilities. We recommend revisiting threshold settings quarterly and running a quick traffic sample when you've added new workflow nodes.
If you're building autonomous AI agents or AI coding agents that run continuous tool loops, cost optimization becomes even more critical; those workloads can spike inference spend faster than any customer-facing bot. Start with caching + cheap-tier routing on the repetitive classification calls, and reserve top-tier capacity for the reasoning steps that actually need it.



